

마지막 5주차 강의에서는 백테스팅 전략 두 가지를 배웠다.
두 가지 전략 중 첫번째는 변동성 돌파 전략이다.
이번 편에서는
변동성 돌파 전략에 대해 알아보고,
buy, sell 가격과 수익률을 구해본 후,
최적의 k값을 구해보았다.
역시나 복잡하니, 코드를 외울 생각을 하기 보단,
기존 코드를 불러와 사용하기를 추천한다.
1. 변동성 돌파 전략
1) 변동성 돌파 전략이란?
- 주식이 막 오르는 것 같다면? 일단 사고 → 그리고 내일 바로 판다.
- 예시) k = 0.5 라고 할 때.
1. 어제 삼성전자의 주가가 최고 120,000원 ~ 최저 100,000원 이었다.
2. 오늘 삼성전자의 주가가 105,000원으로 시작했다.
3. 오늘 (120,000 - 100,000) ⇒ 20,000원 x 0.5 = 10,000원 오르면 산다.
4. 여기서 0.5는 `k` 값이라고 불리는데, 적당히 넣어준다. (통상 0.4~0.6)
5. 즉, 105,000 + 10,000 = **115,000원이 되면 산다.** 오르는 `분위기` 라고 판단.
6. 역시 오르는가 싶더니 오늘 마감 때 **130,000원이 됐다.**
7. 내일 바로 판다.
→ 수익: 130,000 - 115,000원 =15,000원
→ 수익률: 15,000 / 115,000원 = 13%
2) 그림으로 이해하기
- 즉, 어제 변동한 것의 특정 비율만큼 오늘 올랐으면, Buy → 내일 열자마자 Sell

2. 주가 가져오기
1) 라이브러리 설치
- 주가를 가져올 때는 세 개(yfinance, pandas-datareader, finance-datareader)만 설치하면 된다.
!pip install yfinance pandas-datareader finance-datareader

2) 주가 가져오기
- 외울 필요 없이, 아래 코드를 붙여 넣기만 하면 끝난다.
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
import numpy as np
import pandas as pd
import FinanceDataReader as fdr
df = fdr.DataReader('005930','2018')
df.head()

3) 살펴보기
- `df = fdr.DataReader('005930','2018')` 부분 부터는 코드 박스를 분리해서 써준다.
- 그래야 매번 굳이 라이브러리를 다시 로딩 할 필요가 없다.
- `Open: 시초가` `High: 고가` `Low: 저가` `Close: 종가` `Volume: 거래량` `Change: 변동` 값을 확인한다.

3. 사야하는 날, 파는 날 가격 구하기
1) 사야하는 가격 구하기
* 구현 전략을 이해하기
- 우선, `오늘 사야 하는 날인가?` 를 구분하는게 중요하다.
- 그러려면, `사야하는 가격`(=변동성 돌파 가격을 넘었는지)을 확인하는 게 필요하다.
* 사야하는 가격 구하기
- 사야하는 가격 = (어제 최고가 - 어제 최저가) * k + 오늘 시작가
- 오늘 시작가에서 어제 진폭의 k정도가 올랐다면 사야한다는 의미다.
* 코드로 구해보기
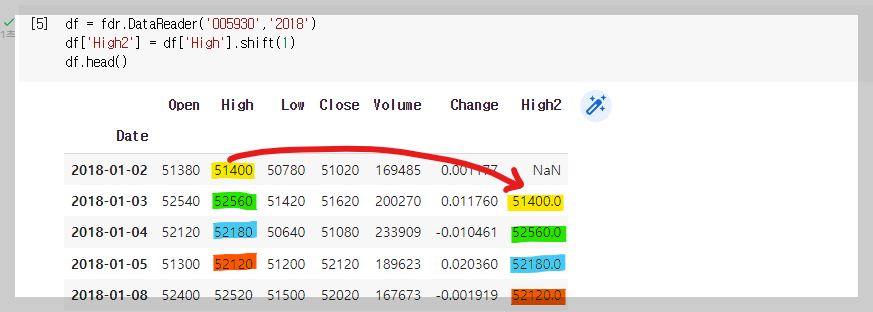
- 일단 .shift()를 이용해서, 어제 High(최고가)를 한칸씩 뒤로 한 새로운 열을 만들어본다.
df = fdr.DataReader('005930','2018')
df['High2'] = df['High'].shift(1)
df.head()
- `buy_at` 열을 만들어 붙여본다. > 사야하는 가격 = (어제 최고가 - 어제 최저가) * k + 오늘 시작가
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df

2) 사야하는 날 & 파는 가격 구하기
* 사야하는 날인지 파악하기
- 오늘 장 중에 사야하는 가격을 넘었다면, 사는 것이다.
- 즉, 오늘 'High(최고가)'가 ‘buy_at(사야하는 가격)'을 넘으면 사야하는 날이다.
* 사야하는 날을 구하기
- `buy_at` 가격과 `High` 가격을 비교하면 된다.
- `is_buy` 열을 만들어본다.
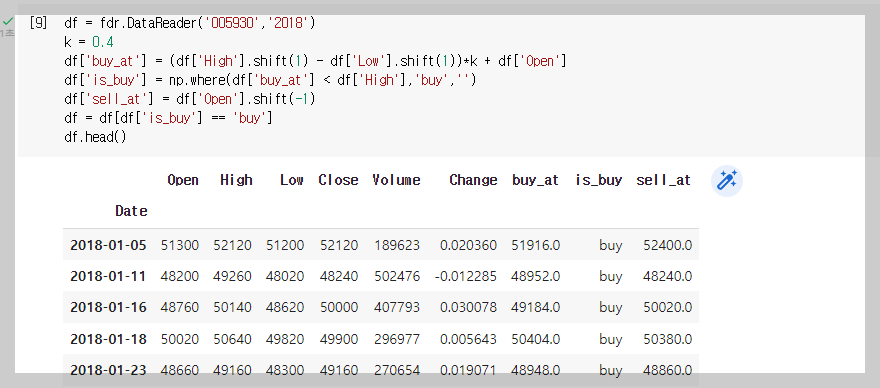
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['buy_at'] < df['High'],'buy','')
df

* 팔아야 하는 가격 구하기
- 변동성 돌파 전략은, 샀으면 다음날 장이 열리자마자 Open가에 파는 것이다.
- `sell_at` 열을 만들어 붙여본다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['buy_at'] < df['High'],'buy','')
df['sell_at'] = df['Open'].shift(-1)
df

3) 수익률 구하기
* 구현 전략을 생각해보기
- `is_buy` 가 있는 행들만 추린다.
- `buy_at` → `sell_at` 가격으로 수익률을 구하면 된다.
* `is_buy` 가 있는 행들만 추리기
- is_buy에 'buy'로 되어있는 행만 추려본다.
df = df[df['is_buy'] == 'buy']
* 수익률 열을 추가해주기
- `return` 열을 만들어 추가해준다.
- `return` = `sell_at` / `buy_at` 이다.
df['return'] = df['sell_at']/df['buy_at']

- `return` 값만 추려본다.
df = df[['buy_at','sell_at']]

* 누적곱을 통해 수익률을 구하기
- .cumprod() 를 사용하면 된다.
- .iloc[ , ]를 이용해 누적곱의 제일 마지막 값을 구하고, -1을 해주면 수익률이 나온다.
df = fdr.DataReader('005930','2018')
k = 0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['buy_at'] < df['High'],'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df = df[['buy_at','sell_at']]
df['return'] = df['sell_at']/df['buy_at']
df[['return']].cumprod().iloc[-1,-1] -1

- 위 수익률 2.11은 211%로, 약 두배 벌었다는 의미다.
4. 최적의 k 구하기
1) 최적의 k 구하기
* 함수로 만들기
- 함수로 만들어야, k 값을 바꿔가면서 적용할 수 있다.
def get_return(code,k):
df = fdr.DataReader(code,'2018')
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1))*k + df['Open']
df['is_buy'] = np.where(df['buy_at'] < df['High'],'buy','')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df = df[['buy_at','sell_at']]
df['return'] = df['sell_at']/df['buy_at']
return df[['return']].cumprod().iloc[-1,-1] -1

- 잘 나오는지 코드와 k값을 입력해 실행해본다.
get_return('005930',0.4)

* k 값을 바꿔가며 최적의 값을 구하기
- 0.4부터 0.6까지 0.01씩 높여주도록 한다.
- np.arange(a,b,c)를 실행해본다.
np.arange(0.4,0.6,0.01)

- 다른 k값을 계속해서 적용해보기 위해, for문을 이용한다.
for k in np.arange(0.4,0.6,0.01):
print(round(k,2))

- 최적의 값을 찾아본다.
df = pd.DataFrame()
for k in np.arange(0.4,0.6,0.01):
doc = {
'k':k,
'return':get_return('005930',k)
}
df = df.append(doc,ignore_index=True)
df.sort_values(by='return',ascending=False)

'CODING > PYTHON' 카테고리의 다른 글
| [Python] 5주차_백테스팅 기초(2) : 월-금 전략 (Feat. 스파르타코딩클럽) (0) | 2022.12.20 |
|---|---|
| [Python] 4주차_백테스팅 기초(1) : 골든/데드크로스 전략 구현 (2편) (Feat. 스파르타코딩클럽) (1) | 2022.12.13 |
| [Python] 4주차_백테스팅 기초(1) : 골든/데드크로스 전략 구현 (1편) (Feat. 스파르타코딩클럽) (0) | 2022.12.13 |
| [Python] 3주차_DART 데이터 내 마음대로 활용하기(3편) (Feat. 스파르타코딩클럽) (1) | 2022.12.08 |
| [Python] 3주차_DART 데이터 내 마음대로 활용하기(2편) (Feat. 스파르타코딩클럽) (0) | 2022.12.08 |