

데이터 크롤링부터
엑셀 다루기/파일 저장 및 이름 바꾸기/이미지 다운받기까지
기나긴 실습을 해보았는데,
간단하지만, 어렵다...
쉬워보이지만, 생소하다...
그래서 복습을 철저히 해야겠다고 생각하고 다짐했다.
아래에 실습한 내용을 정리해보도록 하겠다.
[2편]
3. 데이터 크롤링
1) 웹페이지의 동작 방식 이해
- 검색 한 후 페이지 오른쪽 마우스를 누르고, 검사를 누르면 프로그램 언어가 나온다.
- 어떤 서버에서 특정 HTML, CSS, 자바스크립트라고 하는 페이지의 구성요소를 가져오는데, 그걸 그대로 그려주기만 하는게 브라우저의 역할이다.
- 브라우저에서 이름 변경을 하더라도, 내 화면에서만 바뀐 것이고, 새로고침하면 원래대로 돌아온다.
2) 라이브러리 설치하기
- 누군가 만들어둔 라이브러리를 쓰기 위해, 먼저 불러와야 한다.
- !pip install bs4 requests 에서 bs4는 beautiful soup 버전4 (잘 솎아내는 라이브러리), requests는 enter와 같은 의미다.
3) 웹스크래핑 해보기
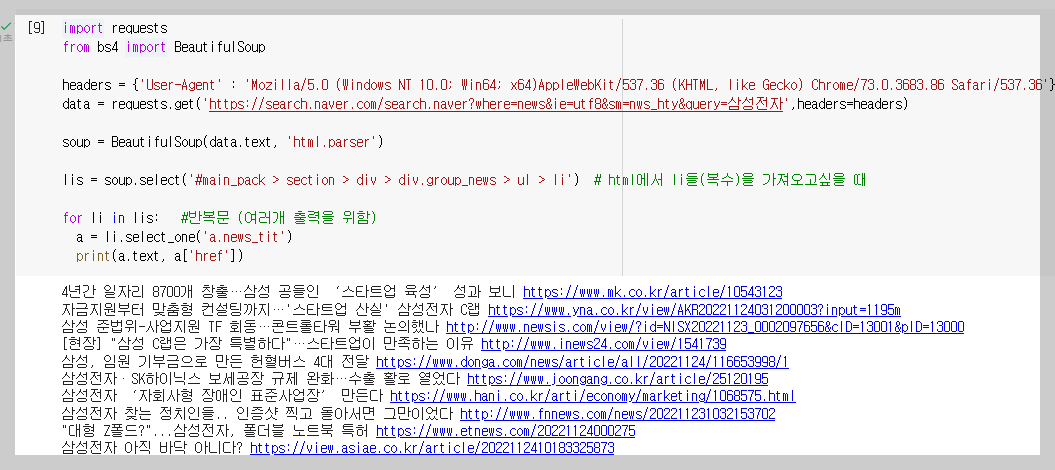
*크롤링 기본 코드는 아래와 같다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
- requests로 정보를 가져오고, BeautifulSoup으로 분석하기 좋게 만드는 것이다.
- a.text를 출력하면 제목(글자)를 보여주고, a['href']는 URL을 출력한다.
* 여러가지 기사 가져오기
- html에서 li들(복수)을 가져오려면 lis = soup.select('#main_pack > section > div > div.group_news > ul > li')를 입력한다.
- 그 안에서 우리가 원하는 a 태그를 가져오려면 a = lis[0].select_one('a.news_tit') 를 입력한다.
- 마지막으로 반복문을 활용한다.
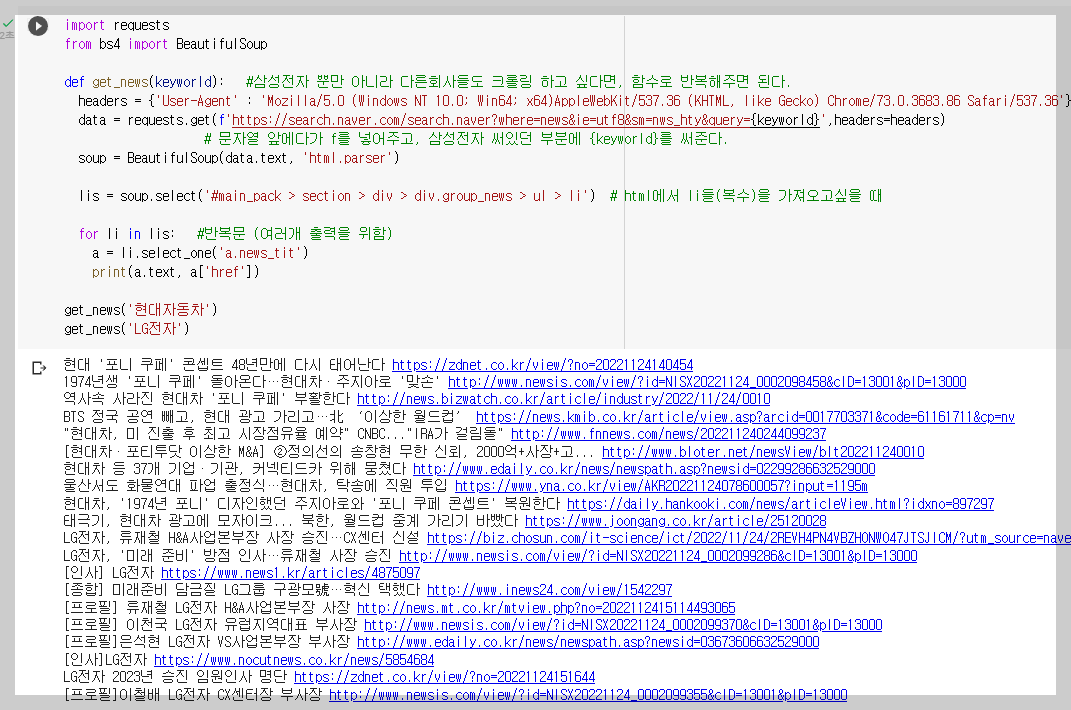
* 키워드가 다른 뉴스 불러오기
- 함수를 만들어 키워드만 바꾸면 다른 뉴스를 볼 수 있다.
4. 엑셀다루기, 파일 저장 및 이름 바꾸기, 이미지 다운받기
1)엑셀 다루기
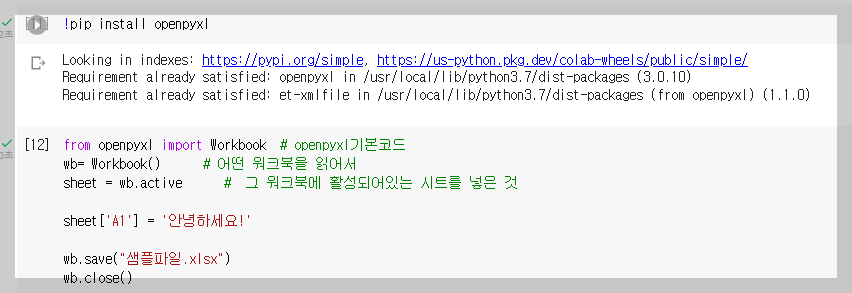
* openpyxl 라이브러리 설치
- openpyxl 기본 코드는 아래와 같다.
from openpyxl import Workbook
wb= Workbook()
sheet = wb.active
sheet['A1'] = '안녕하세요!'
wb.save("샘플파일.xlsx")
wb.close()
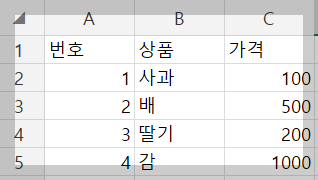
- 엑셀에서 파일을 아래와 같이 수정해본다.
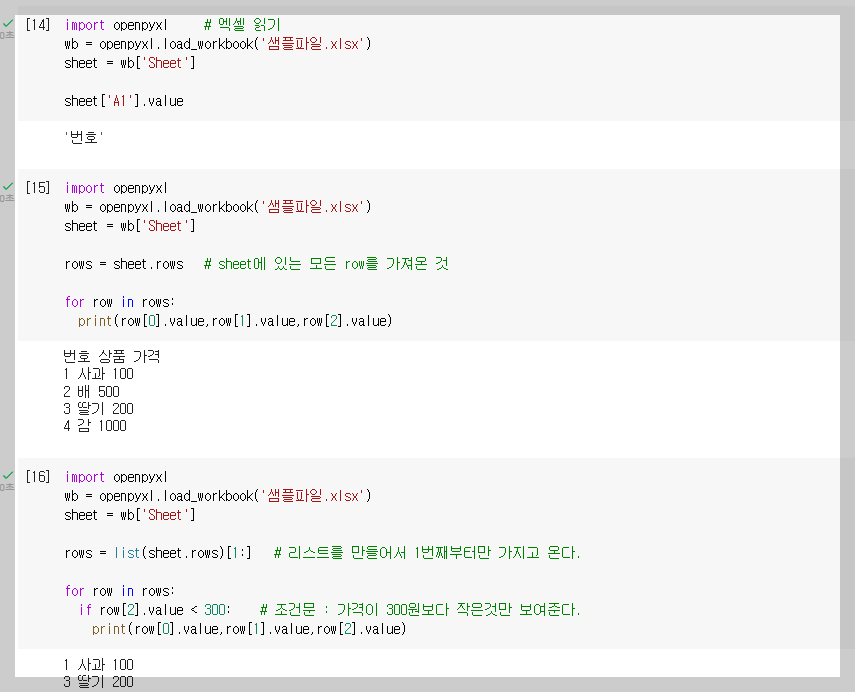
* 엑셀 파일 읽기
- 아래 코드로 엑셀 파일을 읽을 수 있다.
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']
sheet['A1'].value
- 개별 sheet를 읽고 싶다면,
sheet['A1'].value
- 전체 데이터를 읽고 싶다면,
for row in sheet.rows:
print(row[0].value, row[1].value, row[2].value)
- 리스트를 만들어 첫번째부터만 가지고 오고 싶다면,
new_rows = list(sheet.rows)[1:]
- 300원 보다 작은 항목을 출력하고 싶다면,
for row in new_rows:
if row[2].value < 500:
print(row[0].value, row[1].value, row[2].value)
* 스크래핑 결과를 엑셀에 넣기
- 스크래핑 코드와 엑셀 읽기코드를 잘 조합해본다.
- 함수를 만들어 본 후, 반복문으로 여러 파일을 만들어 본다.
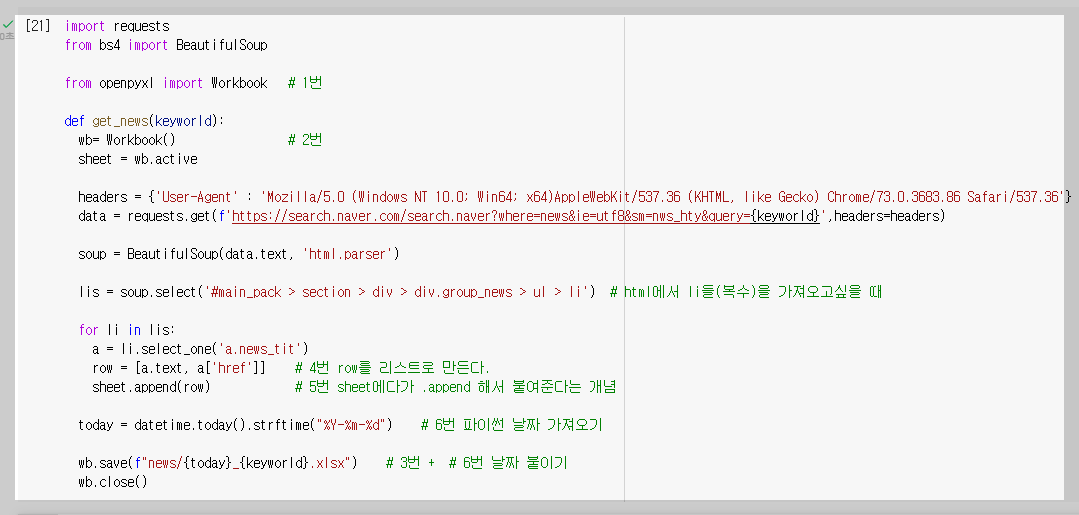
- 파일 저장시 날짜를 붙이기 위해서는 아래 코드부터 실행 시켜야 한다.
from datetime import datetime
datetime.today().strftime("%Y-%m-%d")

- 아래와 같이 스크래핑 결과가 담긴 엑셀 파일이 저장 된 모습을 볼 수 있다.
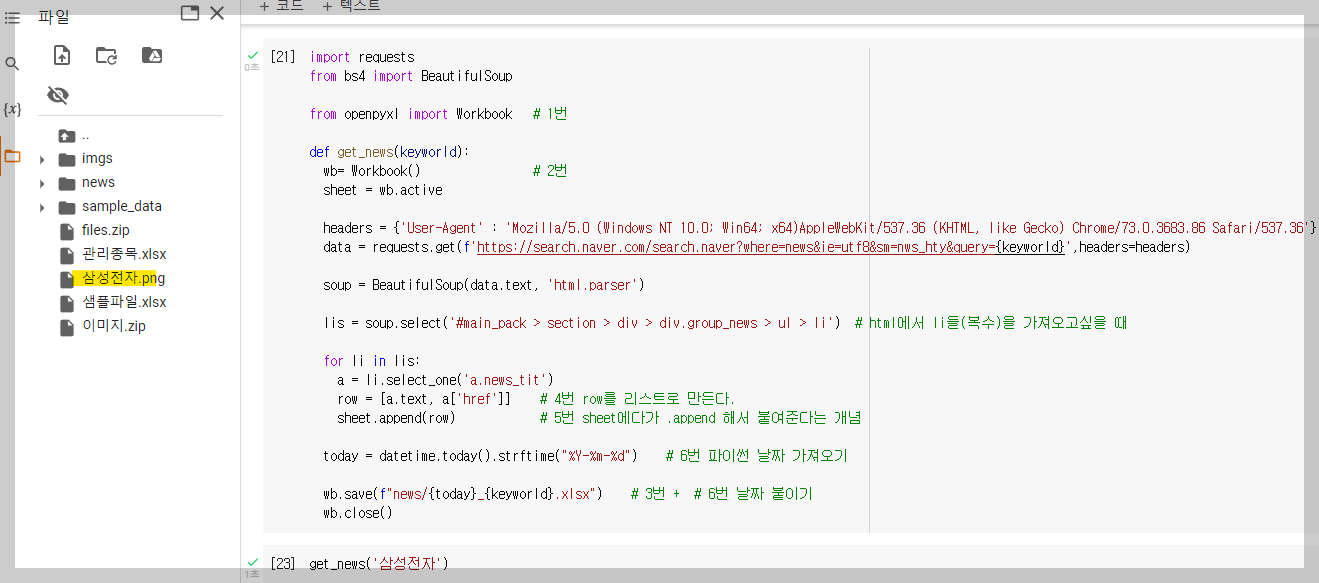
2) 파일 저장 및 이름 바꾸기
* 파일 저장
- 특정 폴더에 파일을 저장하고 싶은 경우에는 news라는 폴더를 일단 만든 후, wb.save(f"{today}_{keyword}.xlsx")를 wb.save(f"news/{today}_{keyword}.xlsx") 로 바꾸어 주면 된다.
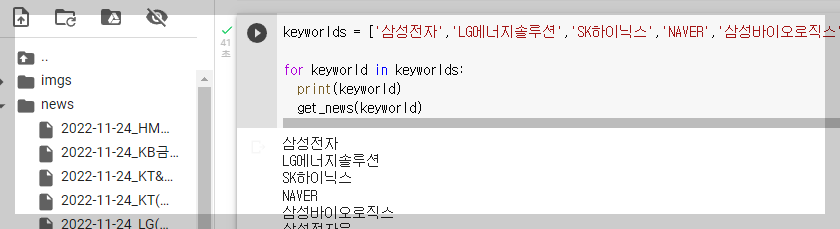
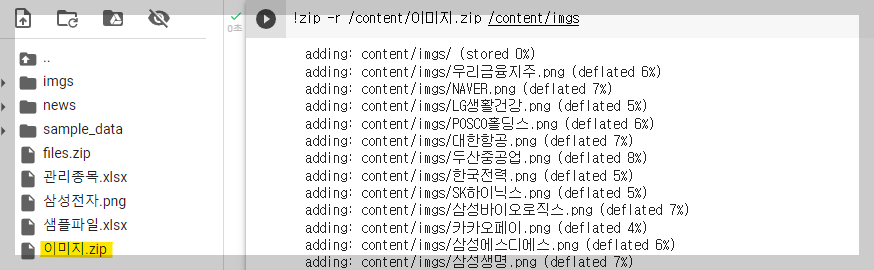
- 파일이 너무 많을 경우 압축 후 다운로드 받는게 일반적인데, 압축 코드는 다음과 같다.
!zip -r /content/files.zip /content/news

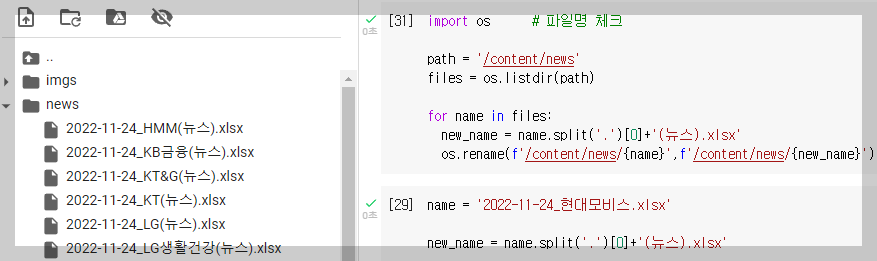
* 파일명 바꾸기
- 파일명 체크하는 코드는 다음과 같다.
import os
path = '/content/news'
files = os.listdir(path)
for file in files:
print(file)
- 변경 할 파일명을 테스트 한 후, 파일명을 변경해본다.
( name.split('.')[0] + '(뉴스).xlsx' 는 ' . '을 기준으로 나눈 후, 0번째 텍스트에 (뉴스)를 붙인다는 의미다.)
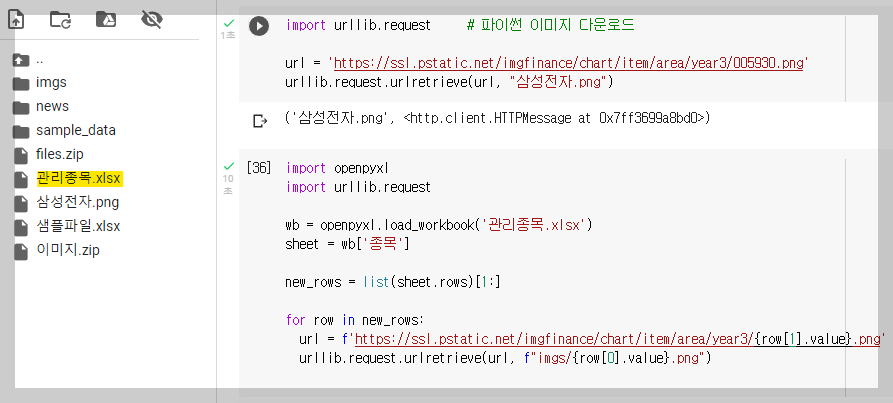
3) 이미지 다운로드
- 파이썬 이미지 다운로드 코드는 다음과 같다.
import urllib.request
url = '여기에 URL을 입력하기'
urllib.request.urlretrieve(url, "test.jpg")
- url은 이미지의 링크를 복사하여 붙여넣기 하면된다.
- 파일의 여러 종목을 한꺼번에 다운로드 하려면, 반복문을 사용한다.
- 여러 이미지를 압축하여 다운로드 한다.
'CODING > PYTHON' 카테고리의 다른 글
| [Python] 3주차_DART 데이터 내 마음대로 활용하기(2편) (Feat. 스파르타코딩클럽) (0) | 2022.12.08 |
|---|---|
| [Python] 3주차_DART 데이터 내 마음대로 활용하기(1편) (Feat. 스파르타코딩클럽) (1) | 2022.12.08 |
| [Python] 2주차_손쉽게 다루는 해외주식(2편) (Feat. 스파르타코딩클럽) (0) | 2022.12.04 |
| [Python] 2주차_손쉽게 다루는 해외주식(1편) (Feat. 스파르타코딩클럽) (0) | 2022.12.01 |
| [Python] 1주차_주식데이터를 활용한 파이썬 데이터 분석(1편) (Feat. 스파르타코딩클럽) (0) | 2022.11.25 |